Getting Twitter posts for Ethereum using an Oracle

This post will show you how to use the Oraclize.it blockchain oracle to get and store Twitter posts for Ethereum smart contracts.
I recently created a end to end working dApp called "Ethereum Twitter Bounty" as the final project for the ConsenSys 2018 Developer Program. In short, this dApp is a bounty contract which allows people to to pay or get paid to make specific Twitter posts. Imagine a decentralized marketing service where companies or individuals can allow normal users to virally market their product by sharing it with their peers on social networks like Twitter.
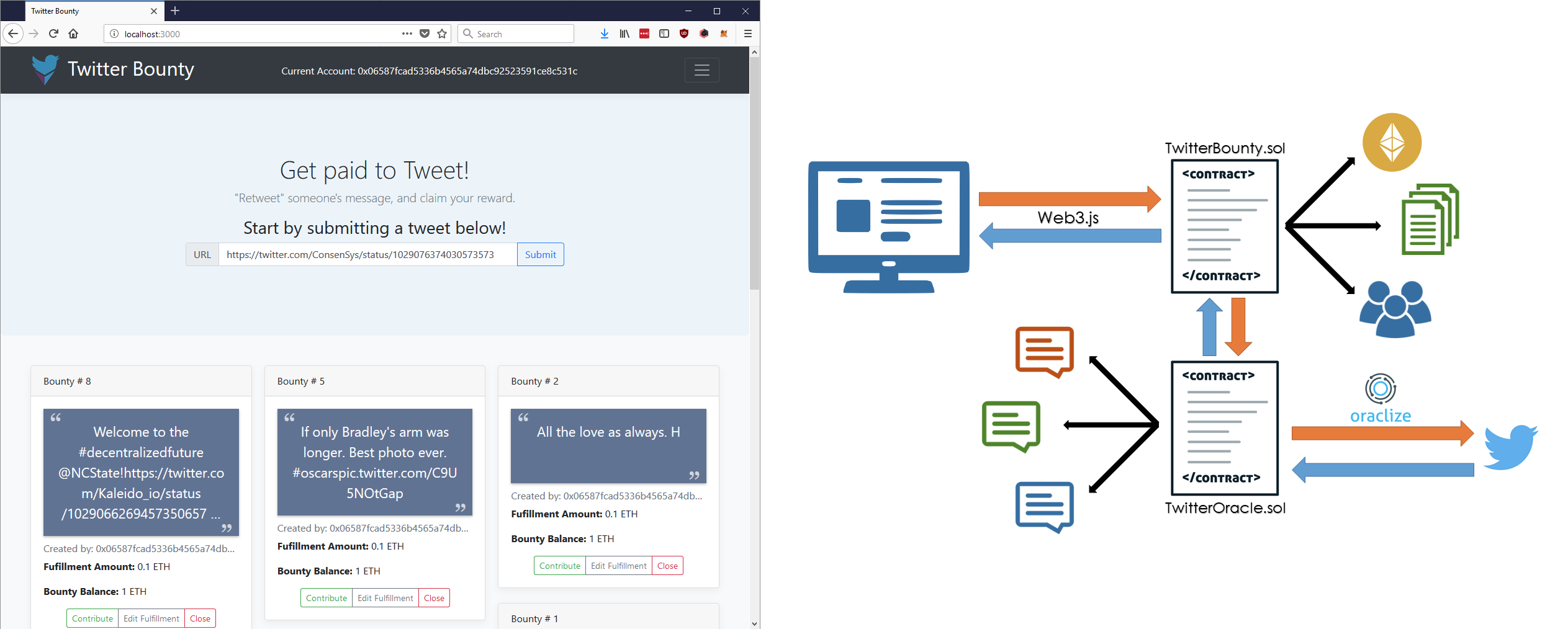
The dApp is broken up into two different contracts: one that fetches and stores Twitter posts on the blockchain and one that manages the bounties and validates the fulfillment conditions.
Fulfillment in this contract is pretty straight-forward: we just need to check that the contents of one post is equal to the contents of another. But before we can even do that, we need to fetch the Twitter posts from the internet, and make them accessible to our blockchain contracts.
That is what we will be going over in this blog post.
Ethereum Oracles
Smart Contracts cannot natively talk to the outside world. Any data which you want a smart contract to access must be available on the blockchain. This is a really common problem that comes up when developing new dApps. Things like the current USD price of Ether, generating random numbers, and finding out the result of a real-world event involves the use of an Oracle: an external service which provides data to the blockchain.
Oracles are actually pretty easy to understand. They simply listen for requests coming from the blockchain for their services, get the data requested, and return it back to the blockchain in the form of a transaction. Anyone could build their own Oracle service and use it for their own personal needs, but that can be pretty complicated or cumbersome for a user who simply wants to create an Ethereum smart contract and not maintain their own cloud service. Additionally, if you are building a decentralized application which uses a custom made oracle, who is to trust that you are not manipulating the results? You start to lose all of the benefits of smart contracts once you delegate results and processes to the outside world.
This is where Oraclize.it comes in. They are an open platform for fetching external data, and providing cryptographic proofs of the results. This is particularly important because smart contracts are often in control of a lot of money, and when it comes to triggering contract code, users should be certain of the data flowing into the contract. Oraclize.it also provides all of the libraries and samples required to get started very quickly, which was super convenient for building my final project.
However, their documentation was a little lacking, specifically when it came to trying out my specific scenario! Here is what they wrote about fetching Twitter posts using their HTML parser:
HTML Parser: helper is useful for HTML scraping. The desired XPATH can be specified as argument of
xpath(..)as shown in the example:
html(https://twitter.com/oraclizeit/status/671316655893561344).xpath(//*[contains(@class, 'tweet-text')]/text())
You can actually try this out really quickly on their Test Query page, and on their particular example, it does work okay... but as soon as you try another Twitter posts, things break down quickly. Here is an example of why this XPATH query is bad:
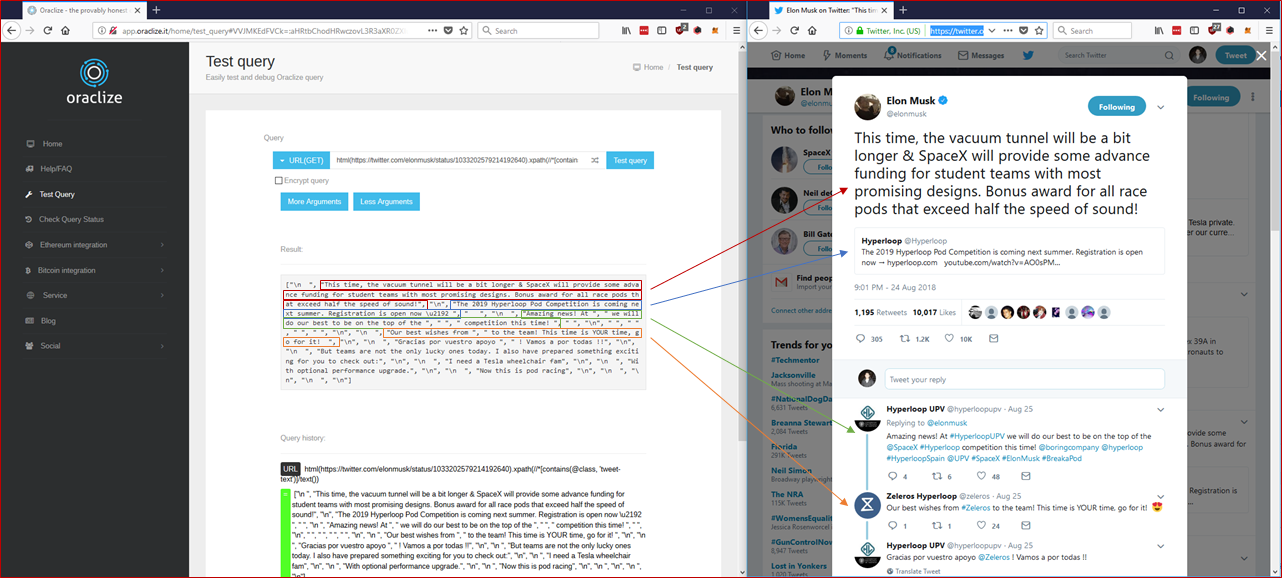
You can see that it is capturing much more than just the original twitter post. All of the replies to the main post also contain the tweet-text class which means that they get picked up by the Oraclize query. Not only does this cost a TON more gas to save to the blockchain, it adds a ton of data which will make it incredibly complicated to validate when a user makes a copy of the post for our scenario. Additionally, some parts of the post like #hashtags and @mentions do not show up, which are also really important for my scenario. So I had to hunt for a better way to parse these posts.
Ultimately, we just need to be more specific about where we grab the text from. Here is an upgraded XPATH query which selects only the main tweet text:
html(https://twitter.com/<username>/status/<id>).xpath(//div[contains(@class, 'permalink-tweet-container')]//p[contains(@class, 'tweet-text')]//text())
The results are much better, but still a little strange... Take a look at this example:
Twitter Post

Oraclize Result
[
"This time, the vacuum tunnel will be a bit longer & SpaceX will provide some advance funding for student teams with most promising designs. Bonus award for all race pods that exceed half the speed of sound!",
"https://",
"twitter.com/hyperloop/stat",
"us/1032818998243520512",
"\u00a0",
"\u2026"
]
Note that we only get content from the main post now (yay!), but we still get this strange array format where things like the linked post are broken up into multiple pieces. To demonstrate more of the weird behavior, look at this other example:
Twitter Post
Oraclize Result
[
"Amazing news! At ",
"#",
"HyperloopUPV",
" we will do our best to be on the top of the ",
"@",
"SpaceX",
" ",
"#",
"Hyperloop",
" competition this time! ",
"@",
"boringcompany",
" ",
"@",
"hyperloop",
"\n",
"#",
"HyperloopSpain",
" ",
"@",
"UPV",
" ",
"#",
"SpaceX",
" ",
"#",
"ElonMusk",
" ",
"#",
"BreakaPod"
]
It is evident that things like #hashtags and @mentions, while present now, are broken up into different pieces. It is pretty easy to repair this on the front end by treating it as a JavaScript array, and then joining the parts:
JSON.parse(result).join("");
/*
"Amazing news! At #HyperloopUPV we will do our best to be on the top of the @SpaceX #Hyperloop competition this time! @boringcompany @hyperloop
#HyperloopSpain @UPV #SpaceX #ElonMusk #BreakaPod"
*/
This final result is perfect, and accurately represents what we want. Unfortunately, on the blockchain, the data is still in this array format, and there is no clean, low gas way to change it that I am aware of.
For my purposes, this can cause some validation issues if there are white-space differences between what the user posts and what the fulfiller used to create their bounty. To avoid this, my suggestion is to keep the posts relatively simple. This will also reduce the amount of gas required to store the post on the blockchain.
The final contract code for my "Twitter Oracle" can be found here. Here is a relevant snippet:
/// @notice This function initiates the oraclize process for a Twitter post
/// @dev This contract needs ether to be able to call the oracle, which is why this function is also payable
/// @param _postId The twitter post to fetch with the oracle. Expecting "<user>/status/<id>"
function oraclizeTweet(string _postId)
public
payable
whenNotPaused
{
// Check if we have enough remaining funds
if (oraclize_getPrice("URL") > address(this).balance) {
emit LogInfo("Oraclize query was NOT sent, please add some ETH to cover for the query fee");
} else {
emit LogInfo("Oraclize query was sent, standing by for the answer..");
// Using XPath to to fetch the right element in the JSON response
string memory query = string(abi.encodePacked("html(https://twitter.com/", _postId, ").xpath(//div[contains(@class, 'permalink-tweet-container')]//p[contains(@class, 'tweet-text')]//text())"));
bytes32 queryId = oraclize_query("URL", query, 6721975);
queryToPost[queryId] = _postId;
}
}
In this code, you can see I have specified a custom gas limit which is extremely high. The default gas limit for the oraclize_query is 200,000 gas, which was causing "out of gas" errors when trying to store the data in the smart contract. I changed the value to be the gas limit for ganache-cli (6,721,975 gas), which is probably not very smart for production, but I did not really invest time into thinking about what a reasonable gas limit would be, and I just wanted to make sure not to run into errors when avoidable.
Take note of another key implementation detail. I get a queryId as a result of oraclize_query. Then I store this value in a mapping, where the value is the Twitter URL (postId) that is being oraclized. This is important because the oraclization process is asynchronous, so when I get a result back from Oraclize.it, I need to know which post the text is for. I then check the mapping I created for the result with a matching queryId, fetch the postId, and then create a mapping using the postId as the key, and the resulting post text as the value. A little tricky, but totally works! :)
Anyway, I hope you learned something from my little exploration into oraclizing Twitter posts for Ethereum dApp development. Try out my app locally by following the instructions on the GitHub page. If you know of a better way to solve this problem, let me know! Otherwise, if you enjoyed this content, feel free to take a look at my donations page.